LLM for Education 调研
近年来,随着大规模语言模型(LLM)的迅速发展,人工智能在教育领域的应用正迎来前所未有的机遇。LLM在辅助学生学习、辅助教师教学方面都起到巨大的作用,并允许为学生定制个性化的学习路线。本文基于Squirrel AI的综述文章和收集相关论文的github仓库对LLM for Education进行调研。
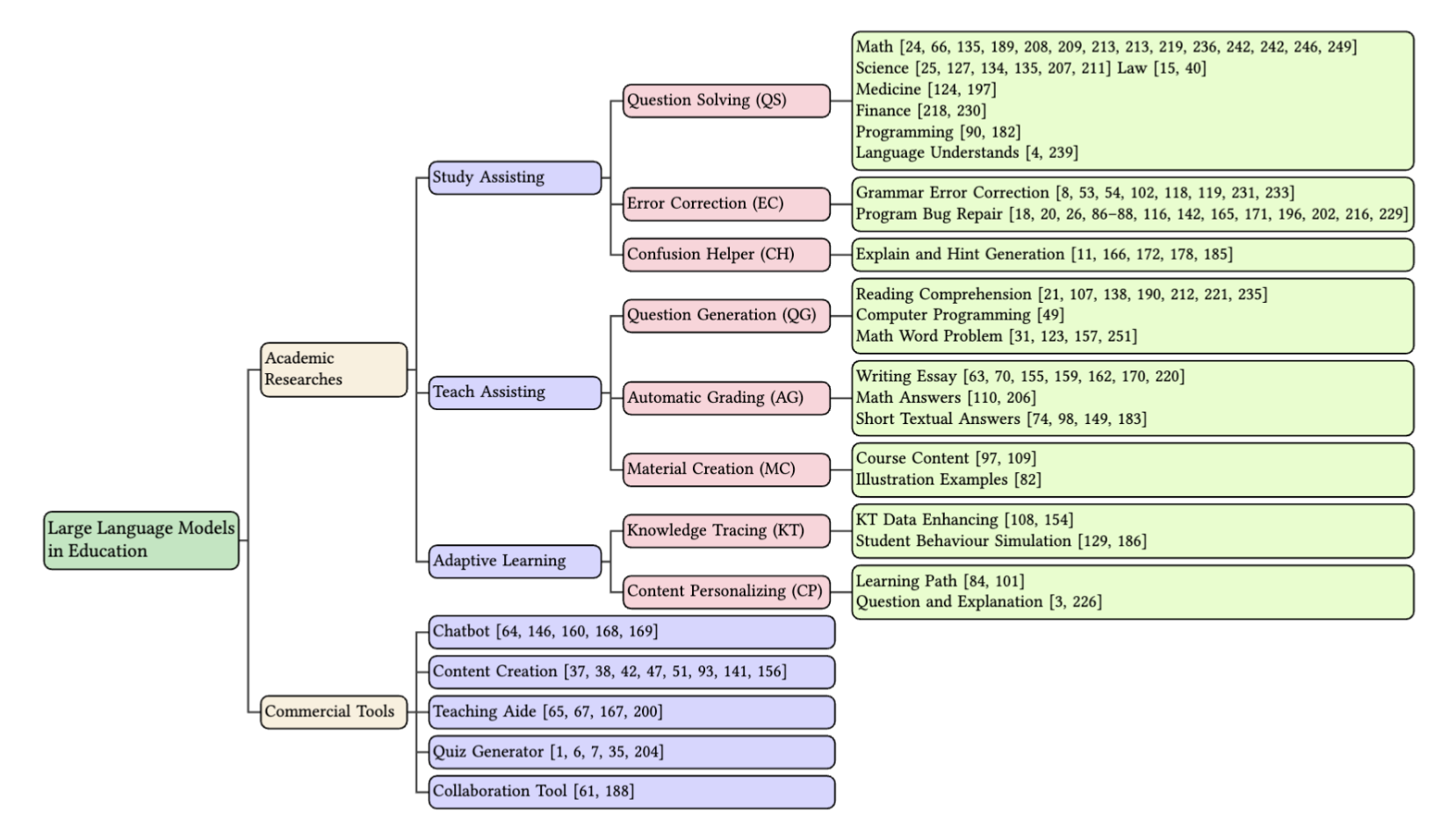
根据综述文章,LLM在教育界的应用主要可以分为四类:首先是学生辅助 (Student Assistance),包括问题求解 (Question Solving)、错误纠正 (Error Correction) 和困惑辅助 (Confusion Helper),旨在为学生提供答疑与个性化反馈;其次是教师辅助 (Teacher Assistance),涵盖问题生成 (Question Generation)、自动评分 (Automatic Grading) 及教材生成 (Material Creation),帮助教师减轻日常教学负担;第三是自适应学习 (Adaptive Learning),利用知识追踪 (Knowledge Tracing) 和内容个性化 (Content Personalizing) 根据学生表现定制学习路径或适应学生水平的材料;最后是具体落地的教育工具包 (Education Toolkit),为构建智能化教学生态系统提供全面支持。此外,AIGC Detection in Education也是一个比较有意思且具有应用价值的领域。下图是综述文章中的分类图。
PS:ACL似乎有过Building Educational Applications的workshop。以及International conference on artificial intelligence in education, AIED 以及 International Conference on Educational Data Mining, EDM 好像认可度也比较高。
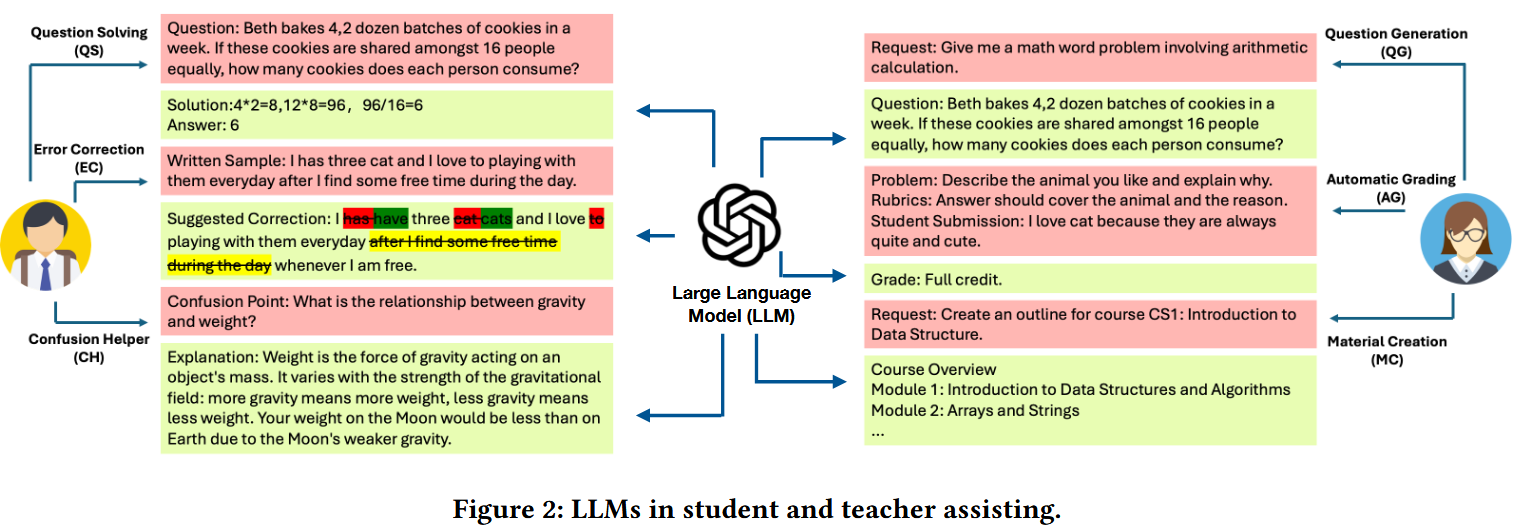
1 学生辅助
LLM通过生成类似于人类的问答能帮助学生解决问题,指出错误或解答疑难问题。
1.1 Question Solving (QS)
实际上感觉不只是教育领域的问题,而是在于提升LLM在某一领域的专业知识以及解决复杂问题的推理能力。一方面可以通过领域适应微调或预训练来丰富专业知识,另一方面可以通过思维链CoT增强推理能力以及强化LLM对指令的理解能力。这些我觉得找一个强大的预训练模型就能做到。为了避免LLM产生运算错误,需要借助外部工具进行计算(PAL: Program-aided Language Models;Solving Challenging Math Word Problems Using GPT-4 Code Interpreter with Code-based Self-Verification)。
1.2 Error Correction (EC)
针对学生提交的文本进行修复,例如修复学生文章或代码的语法错误,依靠微调预训练的语言模型来实现。GrammarGPT利用 LLM 来解决中文语法错误,通过使用混合注释数据集(包括人工注释和 ChatGPT 生成)对开源 LLM 进行微调,所提出的框架在母语中文语法错误纠正方面表现良好。MMAPR使用在代码中训练的大型语言模型(如 Codex)为入门级 Python 编程作业构建 自动程序修复APR 系统(MMAPR),通过在真实学生程序上对 MMAPR 进行评估并将其与之前最先进的 Python 语法修复引擎进行比较,作者发现 MMAPR 可以修复更多程序,并且平均生成更小的补丁。这更贴近于软件工程方向的工作。
关于语法修正有落地应用grammarly。
1.3 Confusion Helper (CH)
与前两个方向不同,LLM不应该直接生成答案而应该生成建议和提示(hint)帮助引导学生自己解决问题。
Automatic Generation of Socratic Subquestions for Teaching Math Word Problems, EMNLP2022 (link) 提出使用苏格拉底引导式提问的方式,对于输入的数学问题输出若干子问题。整套方法包含三个主要模块:内容规划(Content Planner)、问题生成(Question Generator, QG)以及奖励策略(Rewards for Reinforcement Learning)。在内容规划阶段使用轻量的seq2seq模型提取题目中的运算与方程式,然后与原始问题一起输入骨干网络(T5)生成子问题,在此基础上进一步使用强化学习策略进一步提升效果。实验发现在简单问题上表现好而对于复杂的问题,生成的子问题甚至可能具有误导性。
类似的现象在Learning gain differences between ChatGPT and human tutor generated algebra hints (link) 中也被观察到。由LLM生成的对问题的hint与人类教师提供的亦有较大差距。LLM生成的提示通常比较general,且包含学生无法理解的专有名词。
LLM表现较差的原因可能是因为LLM对用户(学生)的知识水平的了解程度较低。为此Know Your Audience: Do LLMs Adapt to Different Age and Education Levels? (link) 在问题中加上表明读者受教育水平的prompt并对输出回答进行可读性分析,评估ChatGPT 与、GPT-3、Flan-T5、BigScience T0模型,发现四个模型(仅通过提示工程)大都呈现出各自固定的可读性输出区间,对于特定年龄、教育程度的提示并没有很好地自适应。当然目前的测评都是基于比较老的模型了,说不定最新的模型能做的更好。
2 教师辅助
教师的日常工作往往包括出题、备课、作业批改、素材制作等重复性任务。LLM 的出现,为教师减负带来新的可能性。在综述文章中对于问题生成Question Generation和教学材料生成Material Creation的内容有所重叠,而且教学材料生成部分综述调研的文章质量都比较低,我们将其直接抛弃,并且列出一些在问题生成和自动评分以外的其他工作。
2.1 Question Generation (QG)
由于在教学实践中经常使用,问题生成 (QG) 已成为 LLM 在教育应用中最受欢迎的研究课题之一。许多工作聚焦于某些特定学科领域,如Language或Computer Science或Math等。
Evaluating Reading Comprehension Exercises Generated by LLMs: A Showcase of ChatGPT in Education Applications, ACL BEA Workshop, 2023, THU (link) 利用 LLM (在课本和补充材料微调gpt2)生成阅读理解材料和问题,并实现了一个允许教师操作和再编辑的系统(很简单的demo)。这个工作还是比较有价值的。
Student Answer Forecasting: Transformer-Driven Answer Choice Prediction for Language Learning, EDM 2024, link 通过real-world German language learning ITS中超过10,000学生的真实选择表现构建学生行为的表示,能够把握学生容易犯错的概念,从而生成更有考察点的多选题MCQ。
A Comparative Study of AI-Generated (GPT-4) and Human-crafted MCQs in Programming Education (link) 收集了四门 Python 编程和两门数据科学相关课程的 246 个模块级学习目标(LOs)将每个 LO 进行自动分类(如“记忆”、“理解”、“应用”等),并基于分类结果来确定具体的题目类型(如简单回忆题、填空题、代码输出题、情景题等)构建提示工程直接让GPT4进行生成,发现GPT-4 生成的选择题与人工题目相差不大,其中 81.7% 的自动生成题完全满足所有质量标准。
Learning by Analogy: Diverse Questions Generation in Math Word Problem, ACL 2023 findings (link) 作者的本意似乎是现在的数学问题数据集只包含“单一问题”与对应“等式/答案”而缺乏可以激发模型类比的多样化能力。所以提出一种包含多种生成模式的Diverse Equations Generator来生成多样的题目。好像对education的问题生成也有点帮助。
LLM也具有生成练习题以外的其他教学材料的潜力。
Generating Educational Materials with Different Levels of Readability using LLMs, link
研究旨在解决教育材料的可读性调整问题,特别是如何根据不同学生的阅读能力生成适当难度的文本。提出了一个“分级文本生成”任务,即根据目标可读性水平(如Lexile评分)重写原始教育文本,同时保持原意。研究使用了三种LLM(GPT-3.5、LLaMA-2 70B和Mixtral 8x7B)进行生成,采用零-shot和少量示例学习(few-shot learning)方法。通过Lexile进行可读性评分。
2.2 Automatic Grading (AG)
在 LLM 出现之前,关于自动作业评分系统的研究就已经提出了。然而,由于先前模型学习能力的限制,大多数现有的自动评分算法如Automatic short answer grading via multiway attention networks (link) 侧重于探索黄金解答和学生答案之间的语义比较(现在的很多生成式模型就是这么被评估的),而忽略了手动评分过程背后的逻辑考虑。除此之外,提供的解决方案的质量对结果有很大影响(标注要求高)。随着 LLM 的出现,上述挑战变得容易解决。
Large language models for education: Grading open-ended questions using chatgpt, 2023, link
Rating short L2 (second-language) essays on the cefr scale with gpt-4, ACL BEA Workshop, 2023, link
以上两个研究首先探索了使用提示微调让LLM分别评分开放式问题和文章写作。通过提供全面的上下文、清晰的评分标准和高质量的示例,LLM 在两个评分任务上都表现出了令人满意的性能。
From Automation to Augmentation: Large Language Models Elevating Essay Scoring Landscape, thu, 2024, link 将 CoT 整合到评分过程中。这种方法要求 LLM 首先分析和解释所提供的材料,然后再确定最终分数。经过这样的修改,LLM 不仅会生成分数结果,还会对学生的答案提供详细的评论,帮助学生学习如何在下一次改进。
LLMs can Find Mathematical Reasoning Mistakes by Pedagogical Chain-of-Thought, IJCAI 2024, link 这篇文章并不是LLM for ED而是ED for LLM。运用教育学的布卢姆认知模型(Bloom Cognitive Model,BCM), 提出一种Pedagogical Chain-of-Thought (PedCoT)的方法用于模型在数学推理中的错误纠正。通过prompt让大模型按照数学概念、解题思路、计算过程的步骤去分阶段思考。
Automated Feedback for Student Math Responses Based on Multi-Modality and Fine-Tuning 将评分对象从学生的文本答案扩展到手写答案。通过使用先进的多模态框架(例如 CLIP 和 BLIP),发现学生的文本和图像以及问题的文本和图像的结合可以提高模型的评分性能。(CLIP和BLIP不算LLM吧)
Pronunciation Assessment with Multi-modal Large Language Models, zuoyebang, 2024, link 提出利用“LLM + 语音编码器 + 模态适配器”的多模态方法,尝试让LLM直接根据音频和对应的文本预测发音准确度与流利度分数。
Reducing the cost: Cross-prompt pre-finetuning for short answer scoring, AIED, 2024, link 通过跨题目的数据训练一个模型,并且在新题目上实现良好的评分效果。预微调阶段在已有的多个题目(跨题目数据)上进行模型的预微调。此阶段使用了不同题目的标注数据,这些题目的评分标准和答案内容不同,但可以通过学习通用的评分原则(例如,答案中包含评分标准中指定的信息就会得分更高)来提高模型的泛化能力。然后,使用新的题目数据对预微调后的模型进行微调。此阶段仅使用新的题目数据(不需要访问跨题目数据),目的是让模型适应新的评分标准。类似transfer learning。
2.3 Others
Social Skill Training with Large Language Models, work by cmu, link
论文提出了一个名为“AI Partner和AI Mentor”(APAM)框架的社交技能培训方案。这个框架结合了两种人工智能角色:AI Partner:通过模拟对话,提供情景化的练习和体验,帮助学习者在低风险环境下练习社交技能。AI Mentor:提供基于领域知识和实际经验的个性化反馈,帮助学习者改进其社交技能。
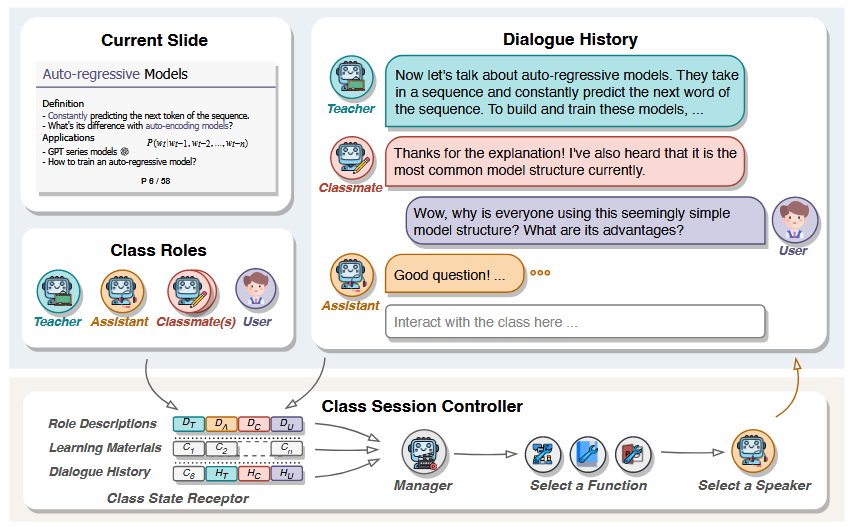
Simulating Classroom Education with LLM-Empowered Agents, work by thu, link
论文提出了一个名为SimClass的多代理虚拟课堂框架。该框架通过引入不同的课堂角色(如教师、助教和同学)模拟课堂上的师生互动和学生之间的互动。每个代理都被赋予了特定的角色和行为,以确保课堂互动的丰富性和多样性。SimClass的设计不仅关注教学内容的传递,还强调通过互动增强学生的学习体验。(那么问题来了,为什么不和真实的老师和同学互动?)
3 自适应学习
知识追踪目标是根据学生在学习过程中对问题的回答的正确性来估算学生知识掌握状态的目标。内容个性化专注于根据个性化因素(例如学习状况,偏好和目标)为学生提供定制的学习内容。可以将LLM与知识图谱结合。
3.1 Knowledge Tracing (KT)
LLM在知识跟踪中的当前使用侧重于根据问题文本和学生使用记录数据生成学生对知识掌握情况的预测(预测学生对特定题目的作答表现或是预测题目的难度等)。本质上还是分类任务。主要用于推荐。
Enhancing Student Performance Prediction on Learnersourced Questions with SGNN-LLM Synergy, AAAI 2024, link 在线教育通过积累大量题目和学生的回答获得了大量的数据。能通过这些历史记录预测学生的做答表现对于个性化学习、智能推荐与后续教学策略具有重要意义。这篇文章提出使用符号图神经网络SGNN(将学生与试题分别视作二部图两侧的节点;学生对题目的回答被转换为“正确(正边)”或“错误(负边)”,从而构造出一个有向二部图。预测学生作答正确或错误即为有向边预测问题)+ LLM提取的题目特征表示完成这一任务。
Difficulty-Focused Contrastive Learning for Knowledge Tracing with a Large Language Model-Based Difficulty Prediction, link 这篇文章尝试预测题目的难度。分别预测题目与概念的难度(即到底是知识点难还是题目难)。用对比学习框架CL4KT对题目的难度进行正负映射。利用MonaCoBERT将题目 ID、概念 ID、难度值(包含正、负两个版本)、学生回答的正误信息等分别映射到向量空间。这篇工作应该是下面两篇工作的杂糅:Monacobert: Monotonic attention based convbert for knowledge tracing 和 Contrastive learning for knowledge tracing。
Estimating Difficulty Levels of Programming Problems with Pre-trained Models, link, 论文提出了一种自动化评估编程题目难度的方法,通过充分利用题目描述的文本信息以及示例代码的语义,借助预训练LLM来快速客观地预测题目难度。构建了题目文本(BERT)、示例代码(CodeBERT)、和资源限制等多个模态特征的输入。
3.2 Content Personalizing (CP)
最近的教育研究中探索了LLM来创建个性化学习内容(个性化生成)。
Leveraging LLMs for Adaptive Testing and Learning in Taiwan Adaptive Learning Platform (TALP) 根据学生的最新知识掌握诊断结果为学生生成动态学习路径。
An LLM-Powered Adaptive Practicing System 根据学习目标Lo自动为学生生成下一个学习目标的问题。
Contextualizing problems to student interests at scale in intelligent tutoring system using large language models 探讨了LLM在基于学生兴趣的情况下创建情境化代数问题的潜力。通过设计和不断优化提示语(prompt),使 GPT-4 能在不改变原有题目数值和难度的前提下,将题目背景转换为与学生兴趣相关的情境。例如,将原本的代数题目分别转换成与视频游戏、TikTok和NBA等兴趣相关的题目。这有助于改善研究期间的学生参与度和结果。
Knowledge Graphs as Context Sources for LLM-Based Explanations of Learning Recommendations 利用基于聊天的LLM来生成学习建议。从预先定义的教育资源和课程体系中构建KG,提取学习目标、课程、主题和开放教育资源之间的层级结构、语义关系和元数据。将KG中提取的结构化和语义信息转化为文本上下文,嵌入到GPT-4的提示语中。(知识图谱+LLM)
4 教育工具包
现在的很多LLM应用如GPT系列、DeepSeek、Bing Chat等聊天机器人基于RolePlay的提示工程本身就能很好地扮演教师角色。一些其他LLM赋能的工具如Grammarly本身对教育也有所帮助。
综述中列举了一些盈利性质的网站型应用如
-
Diffit: 根据输入的问题教育水平可以生成教材、插图和练习题。并且支持提取其中的一些生词。支持后期编辑。
-
MagicSchool: 集成教师端和学生端的综合平台,包括多种AI工具。声称可以帮助教师制定课程计划、设计作业、生成材料、创建简报和其他几项任务的工具,每周可为教育工作者节省多达 10 个小时的时间。
-
Education Copilot: 使用copilot提供教育相关文档写作的帮助。
等等(感觉都像是会出现在youtube广告中的东西)。我觉得这些的参考价值不大。
5 挑战与发展方向
直接概括了综述中总结的挑战与发展方向。
当前的挑战:
- 偏见和公平性问题:LLM可能因训练数据中的不平衡而产生偏见,影响模型生成的内容的公平性和包容性,尤其是针对不同群体(如少数族裔或非英语使用者)。
- 可靠性和安全性问题:LLM的“幻觉”问题(生成不真实的内容)及其生成有毒、无一致性的输出,对教育应用中的使用造成风险。
- 透明度和问责制:LLM通常是黑箱操作,这导致在教育应用中,用户难以理解模型的决策过程,也增加了抄袭、考试作弊等问题的风险。
- 隐私和安全问题:随着LLM的广泛应用,尤其在教育领域,如何保护学生的个人隐私成为一个重要议题。
- 过度依赖LLM:学生可能过度依赖LLM,削弱了独立思考和学术写作等关键能力,尤其是当学生不进行有效的批判性思维训练时。
未来的发展方向:
- 教育目标对齐的LLM:未来可以利用增强生成技术(如检索增强生成技术,RAG)让LLM更好地与教育目标对齐,产生符合教育需求的输出。
- 多智能体教育系统:使用多个LLM代理共同协作解决教育中的复杂任务,尤其是在自动评分和批改等任务中,通过多代理合作提高任务处理的精确度。
- 多模态和多语言支持:LLM不仅能够处理文本信息,还能结合图像、音频等多模态输入,提供更加丰富和个性化的学习体验。同时,支持多语言的LLM将促进全球教育资源的普及。
- 边缘计算和效率提升:通过在边缘计算环境中部署LLM,可以提高教育技术的效率,并且减少对网络带宽的依赖,保障数据安全。(意义不大,我觉得边缘设备通过联网调api比直接部署更现实)
- 专用领域模型的高效训练:开发适应特定教育领域的专用LLM,通过精准的学科训练,提高模型的专业性和成本效益。