Continual Learning of LLMs 调研
1 引言
语言模型的持续学习研究从2017年左右开始一直与视觉模型一样并行地在展开,尽管前者热度相对后者较低一些,近年来LLM的持续学习还在起步阶段。LLM的持续学习主要分为上游的持续预训练和下游的持续微调。将预训练好的LLM应用至特定专业领域(medical、finance等)但不遗忘通用知识的持续领域适应预训练也有一些工作。
持续预训练的最大现实意义在于可以让LLM随着语料库的更新与时俱进地掌握最新事实。尽管RAG已经作为不错的替代方案出现了,但显然RAG并不能一劳永逸地解决问题。但是由于并非所有团体都有能力做好持续预训练,目前的工作大多不太成熟。
因为语言模型的下游应用更广,这也导致了LLM的持续微调出现了多种五花八门的setting,可以按照微调的方式和微调的任务进行划分。LLM所特有的setting包含持续指令微调、持续模型精炼(主要是持续模型编辑)和持续模型对齐(主要是持续人类反馈强化学习)。LLM的持续微调的热度较预训练更高些,也出现了一些相对成熟的工作。
一个普遍的认知是优秀的特征表示能增强对遗忘的抗性,大多数工作都发现LLM对遗忘的抵抗性很强,只需简单的重放就能取得良好的效果。LLM还有能力自己生成伪数据而避免保存历史样本引发的存储和隐私问题。目前为止大多数工作的backbone在7B规模及以下,GPT2、lamma2、T5等。
主要参考资料(可以参考的论文列表):
Continual Learning of Large Language Models: A Comprehensive Survey [paper] [code]
1.1 Motivation
为什么LLM需要做持续学习?
-
LLM通过预训练获得的静态知识会过时,需要与时俱进地更新。
-
LLM尽管通过预训练获得了通用知识,在特定领域仍需要微调进一步提升性能。(这种情况会多次遇到所以需要多次微调)
在这两种场景下都希望LLM能够掌握新的能力而不遗忘已经掌握的知识,并且只在新数据上训练来提高效率(相较于comian and retrain的做法明显节省开销,很多时候retrain模型或为某些任务单独微调存储模型是持续学习的低效替代方案)。更理想的情况会考虑利用持续学习带来的数据集划分减轻一些数据冲突(例如不同年份某些事实会变化)或通过顺序学习建模鼓励正向的知识迁移(例如先会学某些知识后一些其他知识学得更好)。
PS:我曾经也尝试概括过预训练模型需要持续学习的原因如下图所示:
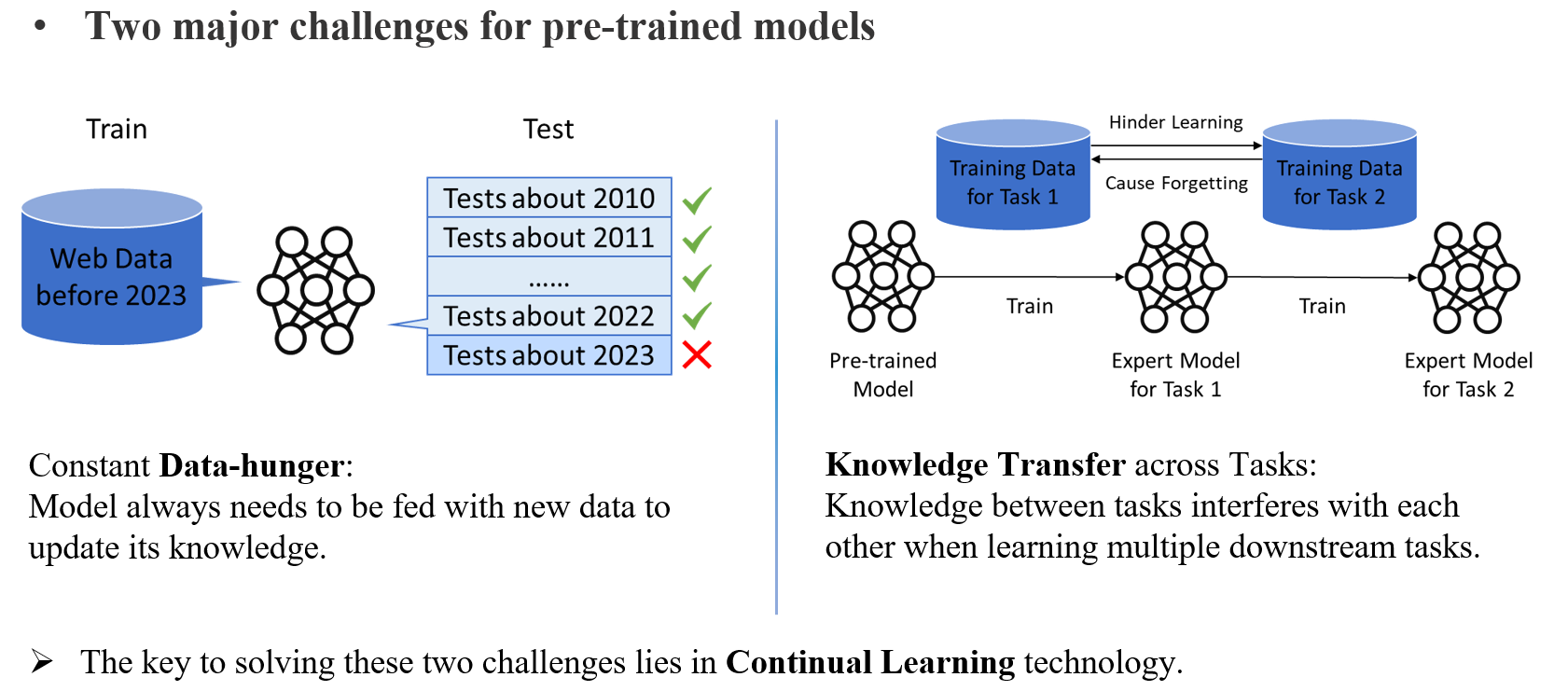
1.2 LLM的持续学习场景分类
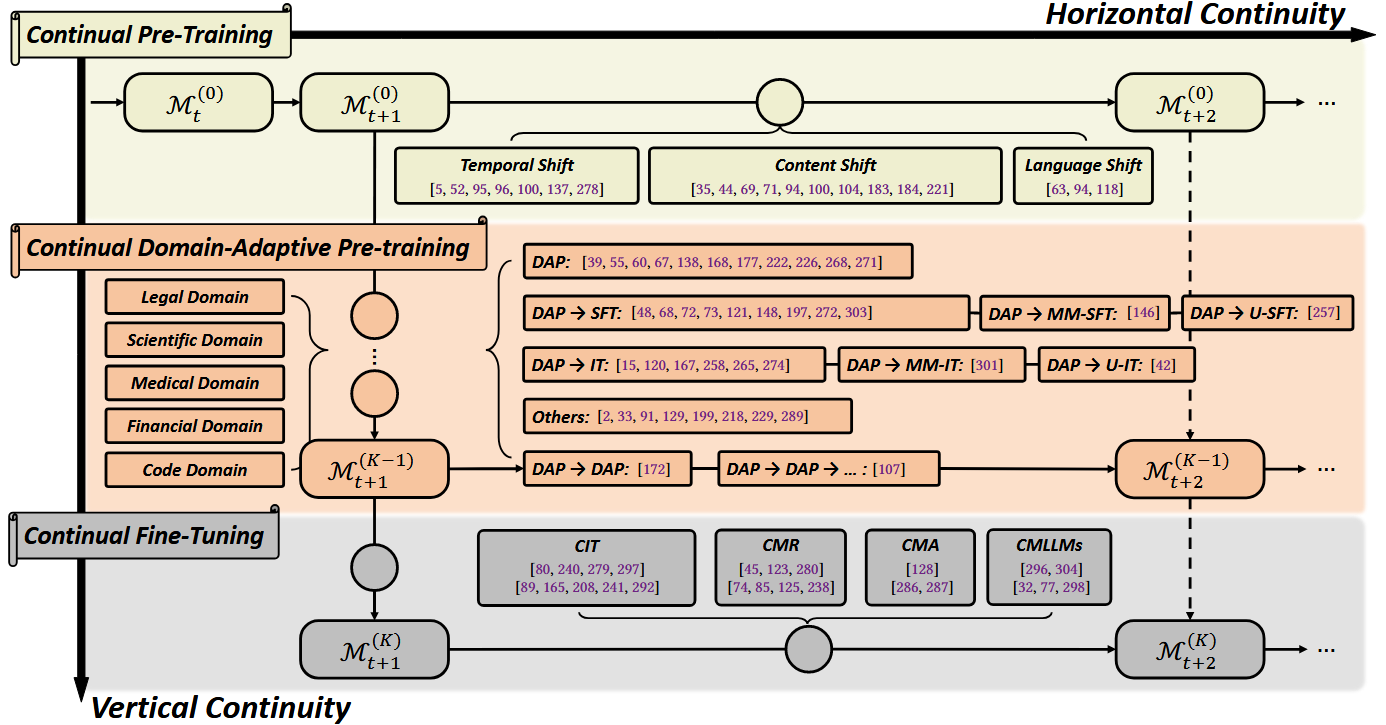
鉴于LLM学习模式的特殊性,LLM的持续学习对以下两种持续性[1]进行要求,对应下图的纵轴和横轴:
纵向持续性:将LLM从大的general domain逐步迁移至小的specific domian的过程(通用预训练->领域适应预训练->进一步下游微调),在此过程中不能遗忘上游通用domian的知识。例如将通用LLM调整成医疗领域专用模型但不遗忘通用能力。
横向持续性:对同一垂直阶段进行水平划分,将训练划分为横跨时间或分布领域的多个训练阶段,不能遗忘历史训练阶段的知识,亦即传统持续学习要求的持续性。这对应着同一垂直阶段的LLM的不断更新,例如预训练阶段用随时间更新的数据更新模型或让模型连续学习多种下游任务。
这种建模类似于[2]中提出的生产者-消费者结构,横轴代表生产者端的持续学习,不断发行新版本的LLM,而纵轴代表消费者端的持续学习,在得到每个发行版本的LLM后,可以将其向用户需要的应用领域上不断迁移。(我估计综述[1]讲故事的方式很大程度受到[2]启发)
[1] Continual Learning of Large Language Models: A Comprehensive Survey. arXiv24
[2] Recyclable tuning for continual pre-training. arXiv23
在此基础上,可以将持续学习场景按照纵向和横向分别进行分类。
垂直领域分类:按将LLM从通用领域向下游专业领域不断适应的不同的学习阶段划分为:Continual Pre-Training (CPT), Domain-Adaptive Pre-training (DAP), and Continual Fine-Tuning (CFT)。
水平领域分类:按同一垂直领域中持续学习的不同的训练阶段组织方式进行划分。这个分类方式类似于传统持续学习中任务增量、领域增量和类增量的划分方式。在CPT中包含temporal, content-level, and language-level。而在CFT中包含Continual Instruction Tuning (CIT), Continual Model Refinement (CMR), Continual Model Alignment (CMA)。这对应了为了满足不同需要的几种主流的微调场景,指令微调、人类反馈强化学习和模型对齐。
1.3 LLM的持续学习的遗忘
纵向遗忘:在纵向学习的过程中,模型会在学习下游任务的同时遗忘上游知识。由于下游任务与上游任务的异构性(学习目标甚至模型结构不同)会加剧对上游知识的遗忘,最主要指的是对预训练通用知识的遗忘。同时由于上游数据通常无法再获取(上游数据可能由供给者私有),阻止了重放历史数据这一有效防遗忘手段的应用。但是如今优质公开数据集很多,我相信大部分的模型预训练数据本身重叠度很大,用合适的方式从公开数据集中采样可以构建代理预训练数据集。
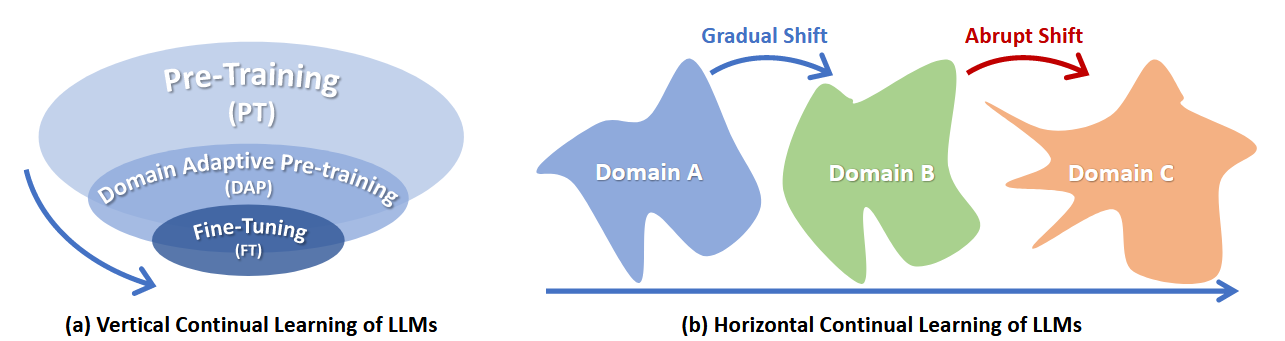
横向遗忘:这种遗忘就是传统持续学习中的遗忘。当任务序列较长或不同的训练阶段的数据包含不同程度的领域偏移(domian shifit)时会尤为严重。其中长任务序列场景我认为在现实中比较少见。
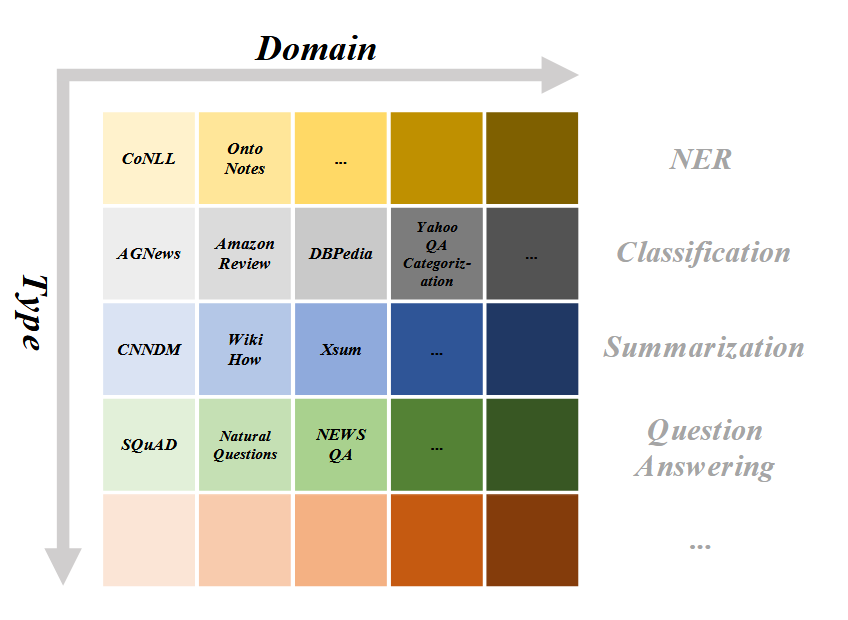
2 持续预训练 CPT
在持续预训练中,考虑的场景并非是一口气在一个静态的数据集上预训练完。而是按照数据的时期(Temporal)、内容(Content)或语种(Language)将预训练数据集划分并构建多个阶段的连续训练。对持续学习训练阶段的划分方式而言,为了更好地衡量遗忘,一般会保证每个阶段的训练数据不重叠,例如传统图像分类任务中每个训练阶段包含不相交的图像类别。其中按时期划分数据更贴近实际应用中不断用新数据更新LLM的场景。
事实上,我看到的CPT工作种很少有提出新的预训练技术的,大多是基于简单基线的测评工作,简单基线可能是直接连续训练、基于简单的传统CL方法或使用PEFT风格的方法。backbone一般基于BERT系列或GPT-2家族或lamma-2。传统持续学习的方法往往是与全参数微调结合使用的,而全参数微调本身会导致比较严重的遗忘,效果不如使用LoRA或Adapter等结构。我认为LoRA或Adapter不适用于长任务序列。尤其是adpter如果需要为每个任务微调一个则在测试时需要知道任务id才能用。
2.1 Temporal Incremental
在静态语料库上预训练的模型需要与时俱进地更新知识解决temporal misalignment问题。与直接的combine and retrain不同,持续学习探索只在新数据上训练的场景来节省开销。与传统持续学习不同的是,模型需要保持时间无关信息的记忆(e.g., 奥巴马的生日),同时更新一些与时间有关的过时信息(e.g., 今年的美国总统是谁),并不是全盘保持记忆。
PS:我认为按时期划分预训练数据集也许可以减轻大时间跨度语料库中因时间变化引起的事实冲突导致的一些问题。
关于此领域的一些问题:
Q1:LLM知识的过时与幻觉有怎样的联系?
Q2:现在工业界的LLM也有纠正错误或过时知识的手段:例如RAG可以使LLM在推理时获取最新信息。使用Prompt也可以告知LLM某些信息。或是使用LoRA+Model Soup来进行长期更新。这些也需要了解。
下面罗列一些具体的工作:
Towards Continual Knowledge Learning of Language Models(ICLR 2022)[paper link]
这是一个benchmaek性质的工作。LLM按时期划分持续预训练时,将LLM需要掌握的知识划分为三种:(1)InvariantLAMA,与时间无关的始终成立的知识,不该被遗忘;(2)UpdateLAMA,需要与时俱进被更新的知识;(3)NewLAMA,未在过去语料库中出现的新学习的知识。
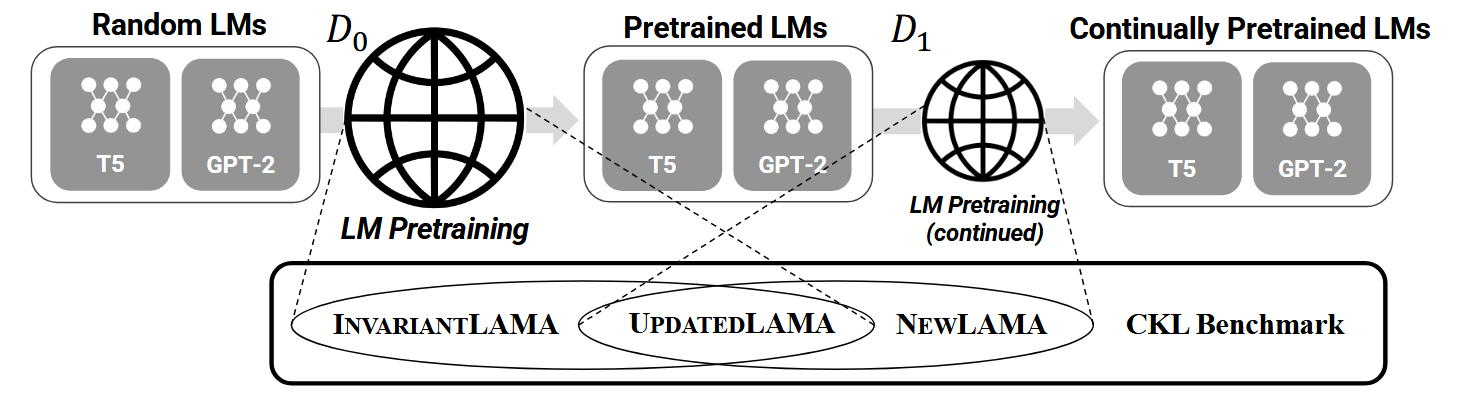
基于此,这篇文章构建了新的benchmark CKL(Continual Knowledge Learning),只包含预训练后的一次继续预训练。其中backbone的预训练数据集为\(D_0\),而一个远小于\(D_0\)的最新爬取的预料库作为\(D_1\)。用填空风格的LAnguage Model Analysis (LAMA) 作为评估任务,分别构建了评估保持时间无关知识(\(D_0 \cap D_1\))、更新过时知识(\(D_0\)与\(D_1\)冲突)、获取新知识(\(D_1 - D_0\))的测试集。
在实验结果中发现使用额外的结构(如LoRA或Adapters)能取得较使用传统的重放或正则化更好的效果。个人认为重放方法对数据的选择很关键,否则可能会重放过时的知识,不利于新知识的学习或更新。同时在训练过程中能重放的数据量远小于预训练本身的数据量,随机采样的数据不一定能代表整个预训练数据集。
TemporalWiki: A Lifelong Benchmark for Training and Evaluating Ever-Evolving Language Models (EMNLP 2022) [paper link]
这篇工作通过英文维基Wikidata每月自动更新的快照构建自动更新的持续学习benchmark,而不同于传统的实质上仍是静态的benchmark。每个新的训练集由更新后的快照所包含的新文章和旧文章的修改部分组成。为了衡量稳性性-可塑性平衡,测试集也由改变的和未改变的部分组成(根据事实元组构建)。
主要实验结果如下,衡量了在未更新部分和更新部分上较初始模型的相对困惑(越低越好)。发现相较PEFT方法,各种全参数微调的方法新任务学习得更好但也遗忘更多。这里RecAdam[1]是应用了正则化技术的CL方法,而Mix-review[2]是应用了重放技术的CL方法。
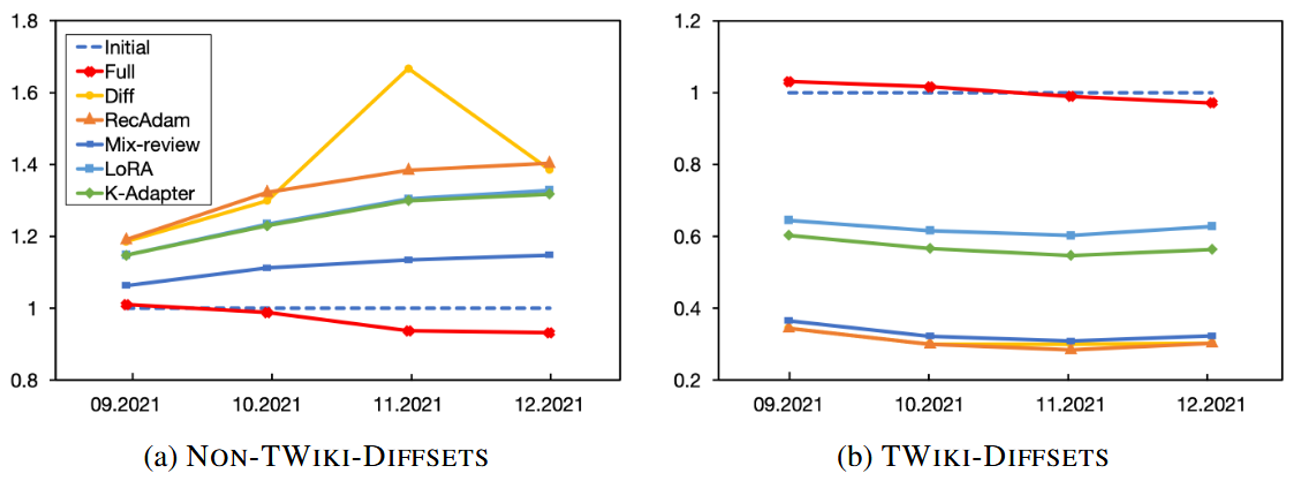
[1] Recall and Learn: Fine-tuning Deep Pretrained Language Models with Less Forgetting (EMNLP 2020) [paper link]
[2] Analyzing the Forgetting Problem in the Pretrain-Finetuning of Dialogue Response Models (EACL 2021) [paper link]
PS:对于CKL和TemporalWiki这两个benchmark,评估的backbone模型还是停留在T5或GPT-2时代,评估的任务也比较单一和简单。如果能建立更加全面的评估,也许能分析出模型的遗忘具体发生在哪些方面,例如knowledge或reliability等。
Time-Aware Language Models as Temporal Knowledge Bases (NAACL 2022) [paper link]
TempoT5提出在每条事实性训练文本前显式地加上时间标识(年份)在预训练时增强模型对时间的感知,从而能减轻时期变化引发的遗忘。这样做模型不再混淆大时间跨度下的预训练语料中因时间变化引起的事实冲突。同时,当只用更新的事实更新模型时,模型也不容易遗忘无需被更新的事实。
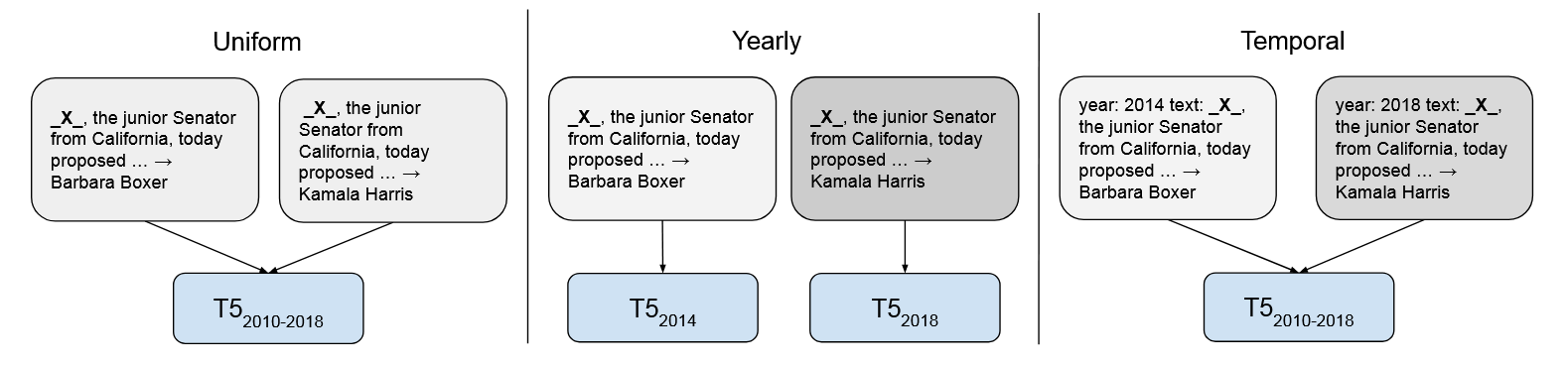
这篇文章的预训练语料是CUSTOMNEWS因而可以从新闻的url中直接提取出时间。但是在很多其他语料中也许很难直接获取时间信息?
TiC-CLIP: Continual Training of CLIP Models (ICLR 2024) [paper link]
Apple的一篇Solid Work,将爬取到的数据按时间划分预训练CLIP,这个setting的目标是持续更新CLIP的知识来应对CLIP的temporal misalignment问题。提出了一个基于重放的简单baseline。
我认为LLM的CPT需要一个像这样的benchmark,包含按年份组织的数据且涵盖广泛的领域。
2.2 Content Incremental
每个持续学习任务的训练语料来自不同的专业domian(因此类似传统continual learning的domain incremental,但是传统CIL中需要推理测试数据来自哪个domain),如News, Social Media, Scientific Papers等。我觉得NLP领域对domain的定义似乎有点模糊?对于这种问题,引入MoE结构似乎比较符合直觉。
Investigating Continual Pretraining in Large Language Models: Insights and Implications (arXiv 2024)[paper link]
这篇文章根据包含最多256 domian的M2D2数据集中的159个domain构建了很长的任务序列。测评的每个模型都是预训练好的。按照任务相似度组织(相似的任务相邻)或随机顺序组织任务序列。发现lamma2在CL后的困惑度比zero-shot时更高了![]() 。没有和joint train比较拿不准效果好坏。个人感觉这篇工作还是缺乏由深度有价值的结论。
。没有和joint train比较拿不准效果好坏。个人感觉这篇工作还是缺乏由深度有价值的结论。
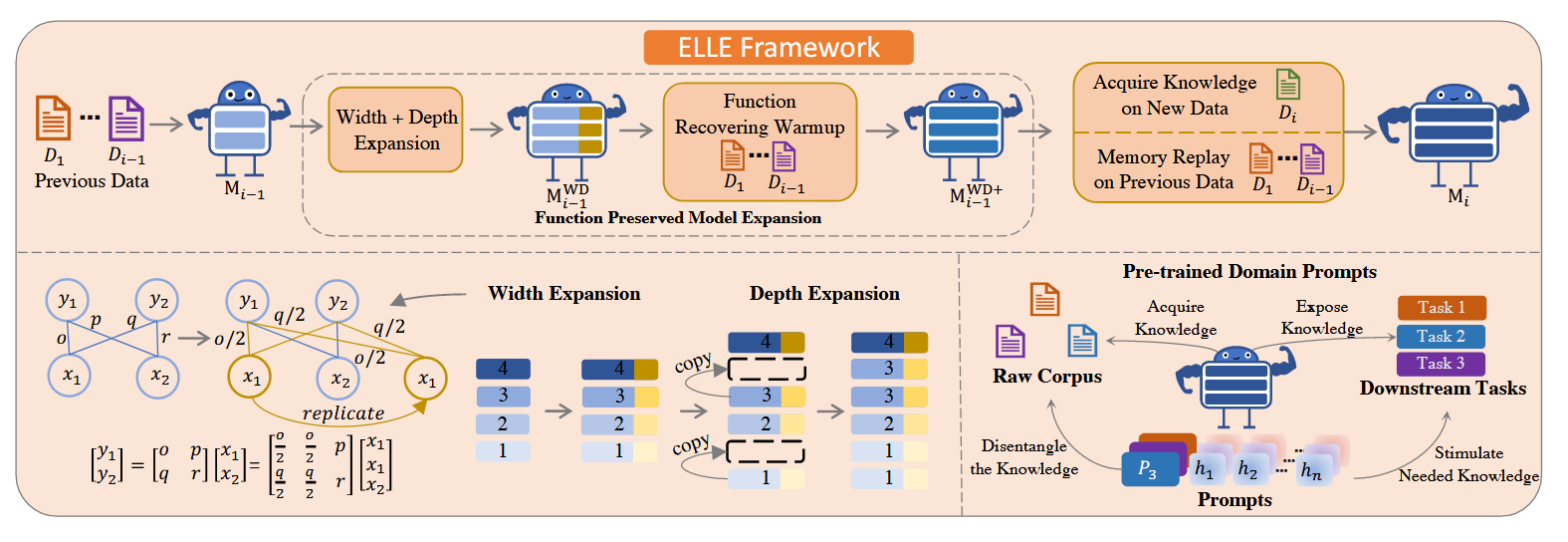
ELLE: Efficient Lifelong Pre-training for Emerging Data (ACL 2022)[paper link]
by THU Yujia Qin
这篇文章比较贴近传统持续学习工作的风格,给整个任务的设定给出了明确的定义,并设计了基于参数扩展和重放的基线。每个task的语料来自不同的文本领域(新闻、网页、文学作品等)。文中使用5个数据集构建这样的任务序列。
为了让模型掌握更多的知识。在学习每个新任务前需要先扩展模型,包括宽度和深度的扩展。宽度扩展要求输出不改变(但被复制),从矩阵运算的角度可以通过线性变换与复制重排参数实现。深度扩展则是随机选择一些层将其复制直接置于原来的位置之后。这样可以在几乎不改变原始输出的前提下扩展模型。为了进一步保证扩展的可靠性,扩展后会通过重放对齐输出。同时为了让模型更好地使用不同的domain,会为每个domain专门配置一组可学习的提示。
Recyclable Tuning for Continual Pre-training (Findings of ACL 2023) [paper link]
by THU Yujia Qin
一篇有趣的工作。LLM本身的预训练权重会被发行方不断的更新。而当更强的新版预训练模型被推出时,用户基于旧版模型在下游任务上微调出的权重可能会被浪费。而直接将这些旧版模型在下游任务微调的参数增量加到新版模型上也能带来明显的下游任务提升。这是一个Linear Mode Connectivity的问题,作者认为持续预训练的LLM的之间具有线性连接性和函数相似性(文中指attention head对相同输入具有相似输出)。针对这个特性,作者提出使用新预训练模型+旧微调模型增量作为后续在同一任务上微调的初始化。文章只讨论了同一下游任务的情形,我觉得还可以扩展到相似domain的任务。
DEMix Layers: Disentangling Domains for Modular Language Modeling (NAACL 2022) [paper link]
by Facebook AI Research
提出使用若干门的feedforward networks FFN代替transformer block中的FFN。在训练时每个domain都会训练专门的FFN。在推理时与其他MoE方法不同的是,设计了一种无需参数的加权方法(按domain全概率展开+Bayes)。这种加权估计在传统持续学习中比较常见,难点在于如何估计每个领域的先验概率,文章介绍了三种做法(uniform、ema、cache)。
Lifelong Language Pretraining with Distribution-Specialized Experts (ICML 2023) [paper link]
引入稀疏门控的MoE机制(在训练和推理时都激活最好的两个专家)。与DEMix Layers不同的是,因为专家的参数被学习新任务时被改写而引入了遗忘,提出使用知识蒸馏来保持历史知识。遗憾的是尽管没有采用等差增长的expert,这篇文章的expert扩展方式仅仅是选择了最优实验结果而未作过多讨论。
Lifelong pretraining: Continually adapting language models to emerging corpora (NAACL 2022)[paper link]
还没看。
2.3 Language Incremental
模型在多个包含完全不同语种的预训练数据集上连续做预训练。也许和multi-lingual的工作有所关联。目前只看到几篇不太成熟的工作。
Continual Learning Under Language Shift (TSD 2024)[paper link]
用英语、丹麦,冰岛和挪威语四种语种构建任务序列并从头持续预训练一个GPT架构的模型。观察到学习完英语后,再学习另外三种语言的效果变得比直接学习每种语言更好了。但是遗忘仍然存在。
Examining forgetting in continual pre-training of aligned large language models (arXiv 2024 ongoing)[paper link]
Hung-Yi Lee手下学生的工作。在将Llama-2-7b-chat在10亿token的繁体中文预料上持续预训练后发现出现严重的重复(repetition)问题。由于Llama-2-7b-chat本身就是由Llama-2-7b微调减轻重复性问题得到(align),所以作者认为这是一种灾难性遗忘现象。而使用\((IA)^3\)代替直接改变预训练模型的参数能减轻这一问题。
Overcoming Catastrophic Forgetting in Massively Multilingual Continual Learning (Findings of ACL 2023)[paper link]
现实的多语种系统应该要具备不断学习新语言的能力。在51个语言的三种任务上测评。发现采用学习率的re-warmup就能大幅减轻遗忘。
2.4 Others
任务组织没有明显特点的其他CPT工作。
Continual Pre-Training of Large Language Models: How to (re)warm your model? (ICMLW 2023) [paper link]
将在Pile数据集上预训练的Pythia 410M模型在SlimPajama模型上继续预训练。模拟的场景是将旧模型在新出的更优质的数据集上继续预训练来增强它。这篇文章主要讨论如何在持续学习的过程中找到重新warm-up的学习率方案,属于偏工程的调参心得。
Rho-1: Not All Tokens Are What You Need (NeurIPS 2024 Oral) [paper link]
在continual pretraining的过程中,由于模型已经具有某些知识,所以每个token的loss变化是不同的,共有四种变化模式(High->High,HIgh->low,low->high,low->low)。这篇工作提出先训练一个参考模型至收敛,然后将后续的模型只在loss明显高于参考模型的token上选择性训练,最后得到的模型具有更强的能力并花费更少的开销。不过这依旧建立在需要一个强参考模型的前提下。
CEM: A Data-Efficient Method for Large Language Models to Continue Evolving From Mistakes (arXiv 2024)[paper link]
Take the Bull by the Horns: Hard Sample-Reweighted Continual Training Improves LLM Generalization (arXiv 2024) [paper link]
3 持续领域适应预训练
侧重于强调在不遗忘同用知识的前提下将模型在某一特定的专业领域进一步预训练(一般只有一个阶段),但仍不能遗忘通用知识。实际上只是持续预训练的分支,但是根据适应的domain不同(medical、finance、code、science等),仍有许多工作能细分出许多类别,故单独列为一项。
(工作太多,看不过来了,后续有空再看)
4 持续微调
持续微调是LLM应用垂直领域的最后一层。
奇妙的是很多工作都claim自己达到了自己setting的upper bound。
4.1 General Continual Fine-Tuning (General CFT)
使用的是全参数微调或PEFT或probing
Achieving Forgetting Prevention and Knowledge Transfer in Continual Learning (NeurIPS 2021)[paper link]
将预训练的Bert持续微调应用于下游分类任务,基于DIL和CIL的方式构建任务序列。采的方法是类MoE机制组合的类Adapter结构。
Can BERT Refrain from Forgetting on Sequential Tasks? A Probing Study (ICLR 2023) [paper link]
发现Bert在下游文本分类任务上微调时任务内的分类不会被扰乱,但是任务间的决策边界重叠了。所以在被告知任务id后进行分类或linear probing性能没有太大退化。通过简单的稀疏重放,BERT在TIL设置上表现出强大的抗遗忘能力。
LFPT5, A Unified Framework for Lifelong Few-shot Language Learning Based on Prompt Tuning of T5 (ICLR 2022) [paper link]
这篇文章研究的是更复杂的持续学习场景,包括学习不同的下游任务(优化目标不同)与同一类型任务中的不同domain。将所有任务都重建为text2text的形式。用不同的prompt来学习不同类型的任务,同一任务的不同种类则用同一prompt持续学习。(这样做不同任务之间似乎不会引起彼此的遗忘)。但是由于需要不同的输出头,不同任务的学习其实是完全隔离的(指令微调可以统一学习)。为了避免学习同一任务的不同domain引起的遗忘,让LLM通过重建loss自己学习生成历史样本进行生成式重放。关于few-shot没有做特别设计,仅仅利用了预训练语言模型的few-shot学习能力。
一边学习下游任务一边学习重建历史样本也是LM独有的能力,在Lamol(ICLR 2019)种被首次提出。
MoFO: Momentum-Filtered Optimizer for Mitigating Forgetting in LLM Fine-Tuning (arXiv 2024) [paper link]
ICLR25拒稿。为了解决模型在下游任务微调时遗忘预训练通用知识,提出只更新动量最大的\(\alpha\%\)参数(类似于选择性微调),从而保持模型落在距离预训练权重较近的局部最优内。这也是基于持续学习的一个经典认知做的。但是我认为减少无用参数更新来减轻遗忘只是一种平凡的现象。当任务间domain gap很大时,这种做法可能就会收效甚微。
这方面有两个比较偏理论的问题:1)特定规则下的选择性调参一定能收敛得和全参数微调相当吗?2)为什么某一特定规则的选择性调参在收敛后较全参数微调距离预训练权重更接近?但是文章没给出很好的回答。
Preserving Generalization of Language models in Few-shot Continual Relation Extraction (EMNLP 2024)[paper link]
Few-shot Continual Relation Extraction作为一种专门的赛道似乎现在有比较明确的benchmark和baseline。在few-shot learning中可能因为数据较少引起过拟合,而过拟合本身会加重遗忘。而已有做法往往是用Bert 等backbone + 下游任务上训练的专门分类器完成这个任务,这样的分类器很容易对新任务产生偏见。这篇工作提出最大化backbone预训练的输出头和下游任务分类器的互信息(这里我没太看懂,应该是两个分布的互信息?)来缓解过拟合。尽管标题上提到了保持泛化,但没有评估模型的通用知识。
Parameterizing Context: Unleashing the Power of Parameter-Efficient Fine-Tuning and In-Context Tuning for Continual Table Semantic Parsing (NeurIPS 2023)[paper link]
针对特定下游任务Table Semantic Parsing的工作,采用上下文学习和PEFT结合的方式。
Learn or Recall? Revisiting Incremental Learning with Pre-trained Language Models (ACL 2024 Oral)[paper link]
研究下游分类任务的持续微调。这篇文章通过linear probing分析发现即使是全量持续微调预训练语言模型,在持续学习过程中尽管下游任务表现观测到了遗忘,其在下游任务上的linear probing表现没有明显退化。说明预训练模型backbone的特征表示具有较强抗遗忘能力,而分类器发生严重遗忘,即传统CL中的class imbalance问题。作者通过实验(将持续微调中的分类器与直接linear probing得到的分类器对比)分析出分类器遗忘的原因是旧类对应的分类器权重被大幅更改了。最后根据观察结论提出一些基于分类器的改进方案,例如冻结旧分类器权重,采用余弦线性分类器消除模长影响等。总的来说算是一篇不错的empirical study。
4.2 Continual Instruction Tuning (CIT)
指令微调是语言模型的一种特殊微调方式,训练数据为表述任务要求的指令(指令中可能含有少量示例)和输入输出的样本。指令微调可行是因为许多NLP任务都可以被统一至text2text的形式。持续指令微调可以允许模型在同一形式的训练下连续学习异构的下游任务(分类、生成等)且减轻对标注数据的依赖,这在其他领域的CL中就很难实现。有些工作也使用仅包含更少上下文示例的纯指令微调来进一步减轻标注负担。由于CIT的backbone很多是zero shot learner,评估时除了微调的下游任务表现,还需要评估分布外的泛化能力。最新工作的benchmark一般基于Sup-NatInst数据集构建。
Q: 指令微调还允许了异构任务的joint training,这种形式的multi-task learning和分开训练比较效果如何?
ConTinTin: Continual Learning from Task Instructions (ACL 2022) [paper link]
首个研究持续指令微调的工作,给出持续指令微调应该要满足的要求。基于NaturalInstructions数据集构建了benchmark,将其中的61个任务划分为初始化任务和持续指令微调的任务。其中初始化任务的预训练数据包含有标注的样本而持续指令微调的任务只包含指令而不包含样本(但指令中可能含有正负示例),想要探讨的问题就是通过指令微调降低对标注数据的依赖。采用负样本训练和重放结合的方式,超过了比较的基线LAMOL。
后续的工作似乎不再考虑只从指令学习的问题,而都会采用一定量的样本。

Fine-tuned Language Models are Continual Learners (EMNLP 2022)[paper link]
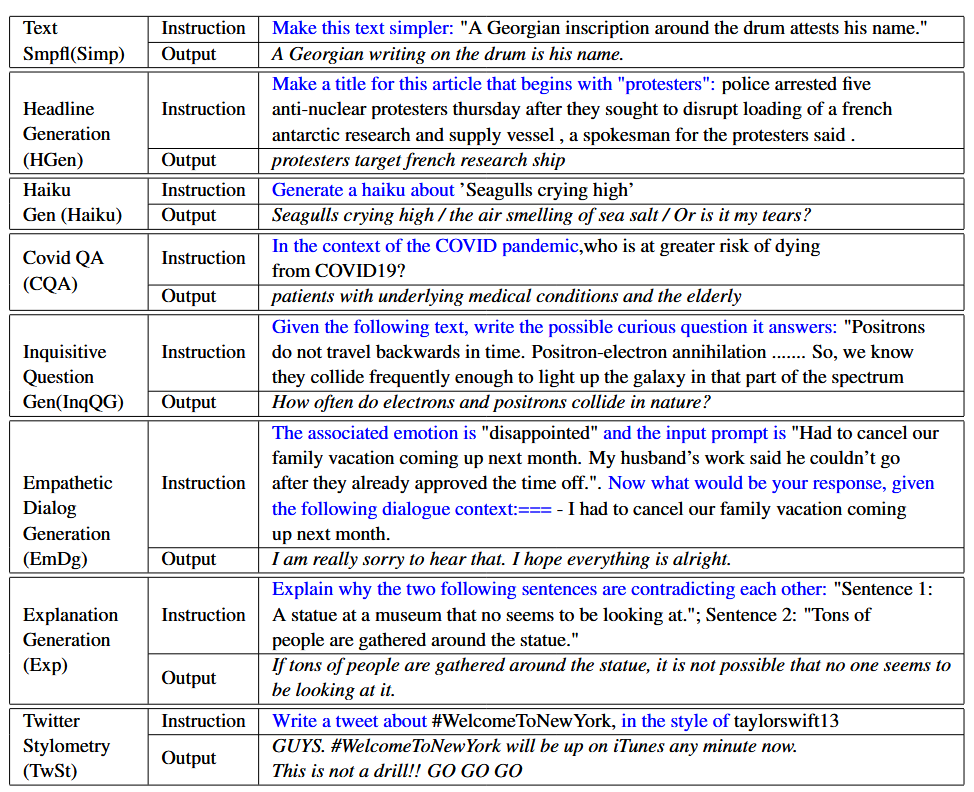
T5在50个数据集上通过大规模指令微调得到具有强大零样本泛化能力的T0,这篇工作探索继续在8个数据集上持续指令微调T0得到CT0,基于1%重放率的稀疏重放(1k个重放样本)。8个数据集对应Text Simplification、Headline Generation with Constraint、Haiku Generation等8种不同任务,但是通过指令微调可以以统一的形式学习。在实验种作者发现重放对保持泛化能力尤其重要,这是因为重放数据源包括了T5->T0的微调数据。最终观察到模型取得了匹敌upper bound的良好下游任务表现和泛化能力。
和ConTinTin比较相似但是同期工作。文章使用的指令的例子:
Large-scale Lifelong Learning of In-context Instructions and How to Tackle It (ACL 2023)[paper link]
这篇文章利用了Sup-NatInst的英文子集构建了更大的持续学习settting,使用500个训练任务和119个测评任务。对于每个训练任务并没有使用训练集中的所有实例,而是只是用100个或1-100随机数量个。在评估时关注学过的指令的实例级泛化和未学过的指令的任务级泛化。提出的解决方案包括约束模型在wide minima的正则化损失和动态重放。保持wide minima的正则化损失有点类似label smoothing。而动态重放则是研究保存什么样的样本用于重放,同时保存高熵和低熵的样本。
我的个人经验是在需要评价泛化的benchmark中label smoothing很有用而会对下游任务表现有一定的牺牲。
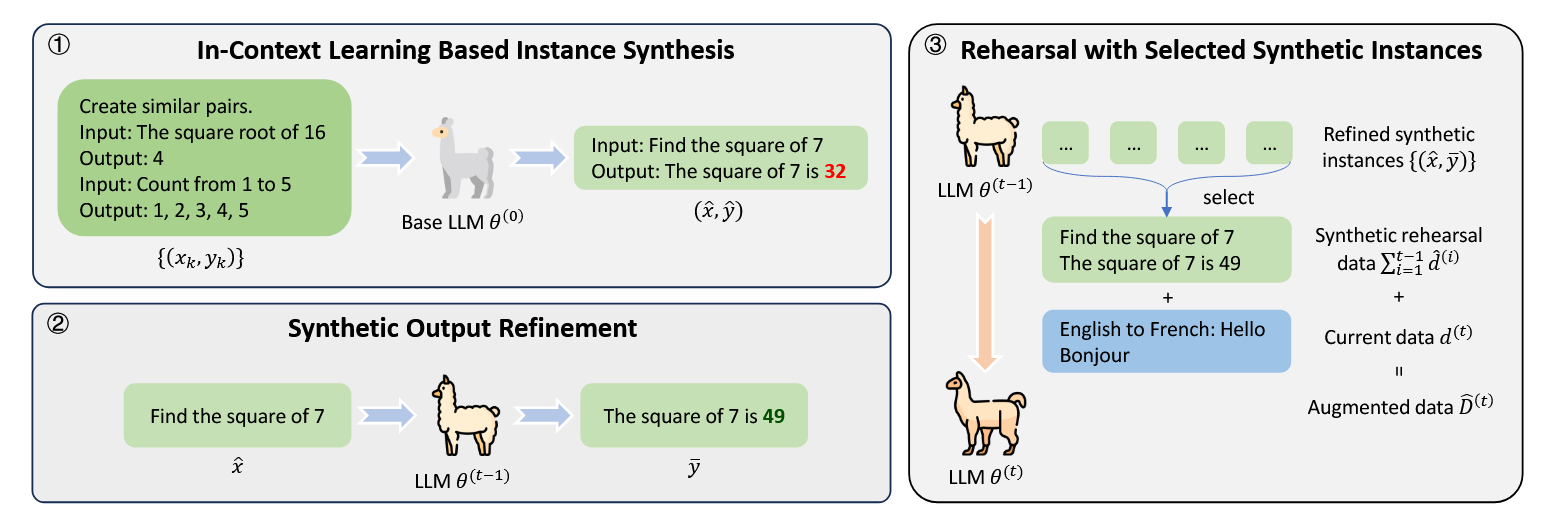
Mitigating Catastrophic Forgetting in Large Language Models with Self-Synthesized Rehearsal (ACL 2024)[paper link]
这篇文章尝试解决重放数据不可获取的情形。采用预训练的模型\(\theta^0\)与上下文学习生成指令学习的伪历史输入数据,并用\(\theta^{t-1}\)修正可能存在的错误。在重放时也进行选择,用聚类确定聚簇中心只重放在聚簇中心附近的数据。
Orthogonal Subspace Learning for Language Model Continual Learning (EMNLP 2023 findings) [paper link]
work by fdu
提出O-LoRA使用LoRA来做持续指令微调。LoRA不同于其他PEFT的地方在于可以将LoRA的参数加回backbone避免参数增长。并没有采用重放而是使用正交正则化来减轻遗忘,想法是使得参数不同任务的更新方向相互正交,为此需要让LoRA的A矩阵列向量张成的子空间正交。
类似于CVPR 2024的InfLoRA: Interference-Free Low-Rank Adaptation for Continual Learning
这种做法的问题在于当任务之间比较相似时,很难做到参数正交。
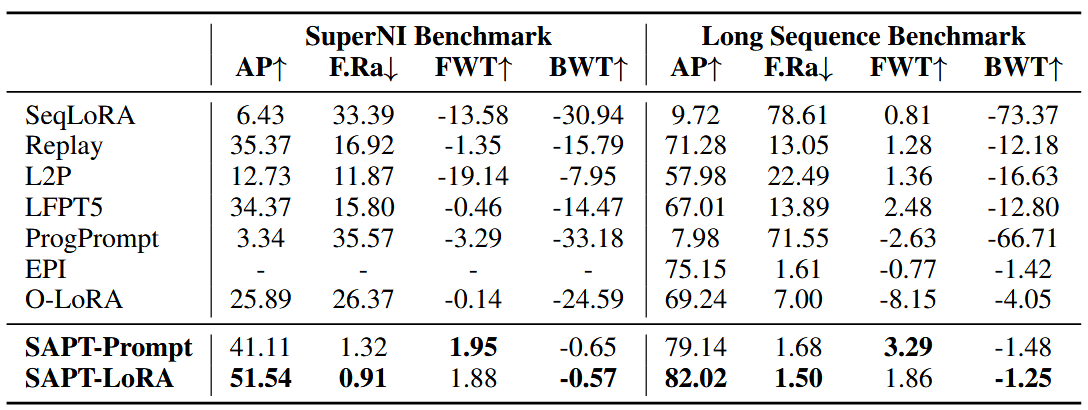
SAPT: A Shared Attention Framework for Parameter-Efficient Continual Learning of Large Language Models (ACL 2024) [paper link]
使用了SuperNI Benchmark和O-LoRA采用的15个分类任务的数据集,用PEFT结合作为学习方式。为每个task单独学习PEFT结构,并通过一个attention block以输入instance为Q,为每个PEFT结构分配的可学习的向量作为K构建查询,最终得到的attention系数对PEFT结构进行加权。为了减轻加权过程中的遗忘,重建伪样本并进行重放。做法类似于CVPR 2023的CODA-Prompt: COntinual Decomposed Attention-based Prompting for Rehearsal-Free Continual Learning。实验中发现LoRA的效果在指令微调数据集上比Prompt要好很多。
InsCL: A Data-efficient Continual Learning Paradigm for Fine-tuning Large Language Models with Instructions (NAACL 2024)[paper link]
对持续指令微调中的重放机制做出改进。使用Wasserstein Distance衡量任务间相似度,加大与当前任务差异大的旧任务的重放数据比例,以此决定每个旧任务的重放规模。在此基础上使用指令指导重放政策。用 GPT-4 给指令打上若干细粒度标签,然后用类似于逆文档频率(IDF)的思路,将指令的复杂度和多样性量化为一个综合度量指标“InsInfo”。越复杂多样的指令,InsInfo值越高。在根据任务相似度分配好每个旧任务需要重放的规模之后,通过 InsInfo 将更多“高指令信息量”的样本选入重放集,从而得到更高效的重放。
实验将将 SuperNI 中的 765 个英语任务整合为 16 个大类,backbone为lamma-7B。
还有两个没火的benchmark工作
- TRACE: A Comprehensive Benchmark for Continual Learning in Large Language Models [paper] [code] (Trace不仅包含指令微调,指令微调只是其中的一条基线)
- CITB: A Benchmark for Continual Instruction Tuning [paper] [code]
4.3 Continual Model Refinement (CMR)
模型在完成预训练被部署的时会被数据流\([x_0,x_1,…]\)不断测试并积累错误。对于其中的错误样本\(x_t, \hat{y}_t= f(x_t)\ne y_t\),我们将其加入到模型精炼的数据集\(\mathcal{X}_{e(rror)}\)中。模型精炼(Model Refinement)就是在测试时错误的数据子集上微调模型并修正错误的过程。
对持续模型精炼(Continual Model Refinement )而言,这个精炼的过程会不断进行,模型需要在不遗忘正确答案的前提下不断修正错误。相较于直接微调模型,更多的方法采用模型编辑技术。对于模型编辑技术而言,可以改变指定样本的输出而不影响到其他样本的输出。这样的setting也被称为Continual Model Editing。
对模型编辑技术而言,实验结果在自己的setting上都做得很好。但是似乎没有文章讨论进行编辑的最优位置。
On Continual Model Refinement in Out-of-Distribution Data Streams (ACL 2022)[paper link]
work by Facebook AI
这篇文章提出了Continual Model Refinement的新setting。NLP服务在离线训练并被部署后,会在OOD的数据流(查询数据流)上被不断使用和测试,并被记录犯错的数据(错误数据流),此时需要模型精炼只在错误的数据上训练,在不引发遗忘的前提下修正错误。
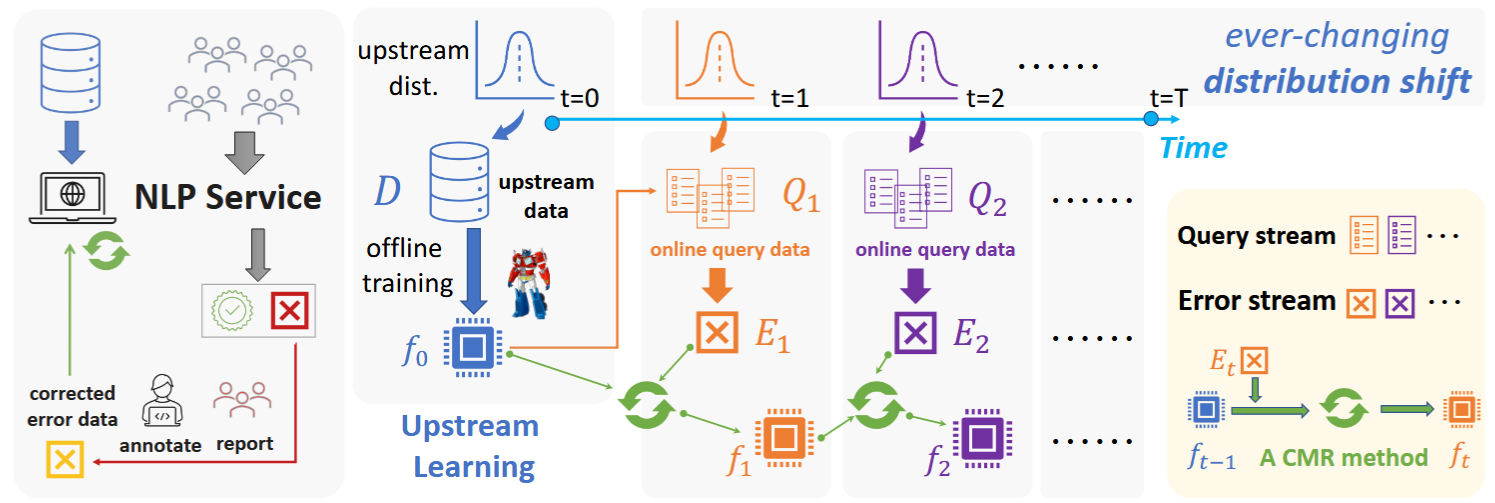
CMR的设定为在线学习。首先有上游预训练。完成预训练后再下游的查询数据流上不断被测试,其中的错误被标注并收集得到错误数据流。模型需要不断修复错误数据流中的错误。作者使用extractive question answering任务MRQA-19的6个数据集构建一个离线上游预训练数据集并用另外5个数据集构建分布外数据流。在此基础上提出了一种通用的采样算法来在多个 OOD 数据集(多个子分布)之间切换或混合生成数据流,并在早期阶段包含一定比例的“上游分布”样本(逐步衰减),以模拟真实世界中数据混杂且分布动态演变的情况。论文设计了五个核心指标以衡量 CMR 方法的性能:
- Error-Fixing Rate (EFR):模型在每个时间步上对当前新错误样本的即时修复率;
- Upstream Knowledge Retention (UKR):模型对初始上游训练数据的记忆保留程度;
- Online Knowledge Retention (OKR):模型对先前流数据里已学会的样本的记忆程度;
- Cumulative Success Rate (CSR):对持续到来的流数据实时预测的累计正确率;
- Knowledge Generalization (KG):模型在额外抽取的、分布相似但未被用于训练的 OOD 测试集上的表现,用于衡量模型对未见样本的泛化能力。
方法部分只基于传统CL方法做了几个简单的baseline。
Aging with GRACE: Lifelong Model Editing with Discrete Key-Value Adaptors (NeurIPS 2023)[paper link]
work by MIT
solid work。使用model editing技术做CMR。提出General Retrieval Adaptors for Continual Editing(GRACE),在模型的中间层加入若干可学习的Adopter结构。Adopter结构缓存错误样本的隐藏层标识并学习新的表示,仅在输入与缓存的隐藏层表示相似时才被激活(通过作用半径阈值控制)。最终实现的效果是只改变需要修正的样本的输出,而其他正确样本的输出不改变。

最终在三个setting上进行了实验T5 进行无上下文 QA(zsRE 数据集)、BERT 进行法律文本多分类(SCOTUS 数据集)、GPT-2 进行文本生成的幻觉修正(Hallucination 数据集)。这三个都是model editing的setting。
Larimar: Large Language Models with Episodic Memory Control (ICML 2024)[paper link]
受到持续学习complementary learning systems理论的启发,使用外部存储器来保存短时情景记忆。在模型推理时,会从存储器中获取对应的记忆来修正输出。由于是一种train-free的方式,取得了更高的效率。存储单元的更新方式类似于Kanerva Machine(这是什么?)。
WISE: Rethinking the Knowledge Memory for Lifelong Model Editing of Large Language Models (NeurIPS 2024)[paper link]
work by ZJU
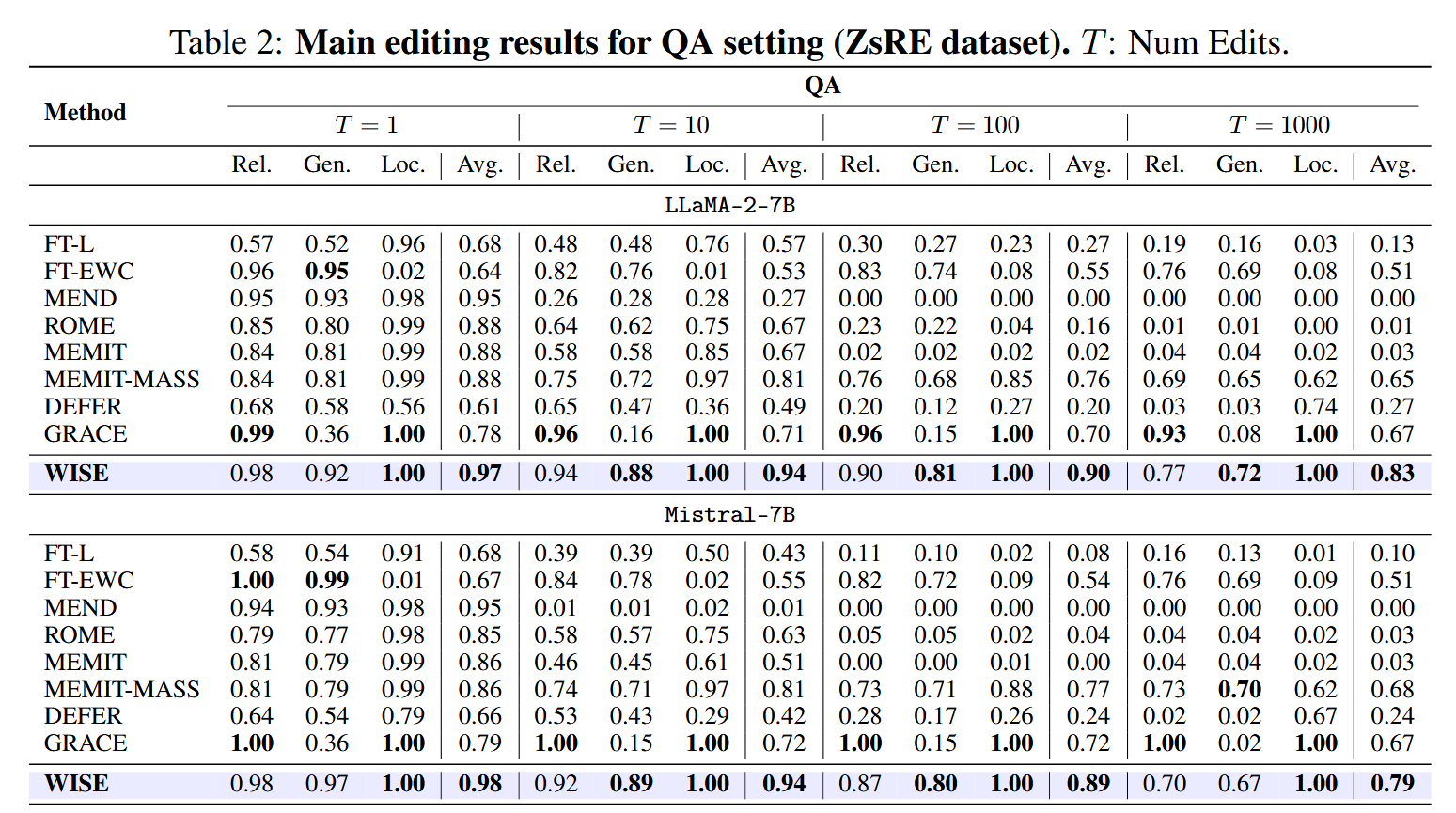
作者认为持续模型编辑中可靠性、泛化性 和 局部性存在不可能三角。这是因为长期记忆(预训练模型参数)和工作记忆(通过检索激活的知识)之间很难权衡。对GRACE而言,基于隐藏层表示相似度的激活方式似乎很难泛化到没见过的样本上。这篇工作提出了WISE,复制LLM的部分FFN作为可编辑的部分,并引入用对比损失训练的路由机制,使得修改后的FFN只在遇到训练集相似样本时被激活。这个想法和GRACE差不多只是训练方式不同。但是这样做已经能保证可靠性和局部性。作者认为保持泛化性的关键在于工作记忆的知识密度,并提出了一种分片和整合的机制保证泛化性。就实验结果而言似乎性能已经很优秀了。但是模型编辑在OOD的任务上的泛化能力依旧比较差(文章table 5)。
4.4 Continual Model Alignment (CMA)
在通过人类反馈强化学习(HFRL)对齐模型或通过微调做伦理对齐时会导致模型遗忘预训练知识,被称为alignment tax,即垂直遗忘。同时RLHF-based LLM本身也需要不断从新的查询和反馈中学习因而存在水平遗忘。Continual Model Alignment的研究同时包含对这两种遗忘的研究。目前的工作主要聚焦于HFRL带来的垂直遗忘和水平遗忘。
Mitigating the Alignment Tax of RLHF(EMNLP 2024)
CPPO: Continual Learning for Reinforcement Learning with Human Feedback (ICLR 2024)
5 数据集和评价指标
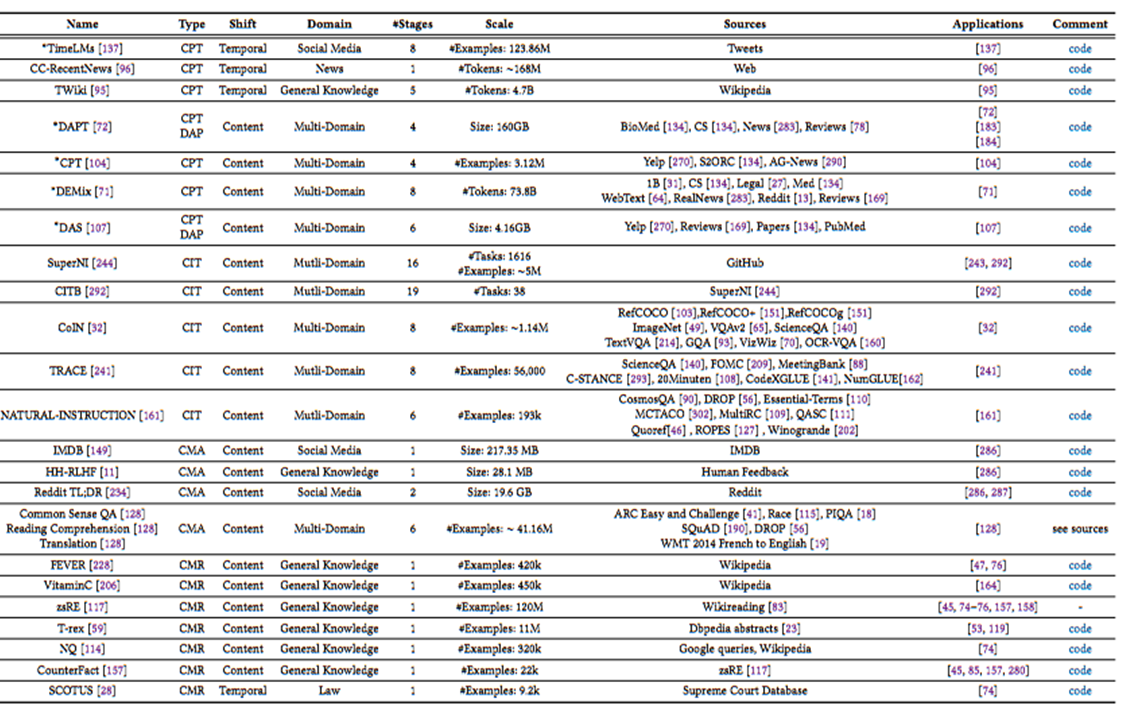
Continual Learning of Large Language Models一文中统计了各种工作使用的benchmark,发现大家基本都是各玩各的。
对于评价指标,一般是在单任务指标的基础上在每个时间步对所有任务进行测试得到下三角矩阵,按照传统持续学习计算Last、Avg.和Forget指标的方式类比计算。由于LLM具有较强泛化能力,一些工作还引入了OOD泛化能力的测评。